
선택 정렬, 버블 정렬같이 사용되지 않는 알고리즘을 공부하는 이유는 무엇일까? chatGPT와 함께 알아보자.
컴퓨터알고리즘 수업시간에 이진 탐색과 시간복잡도를 배운다. 이진 탐색을 통해 빠른 탐색을 위해서는 자료를 정렬해야 한다는 것을 알게 되어 자료를 정렬하는 여러 방법에 대해 배우게 된다.
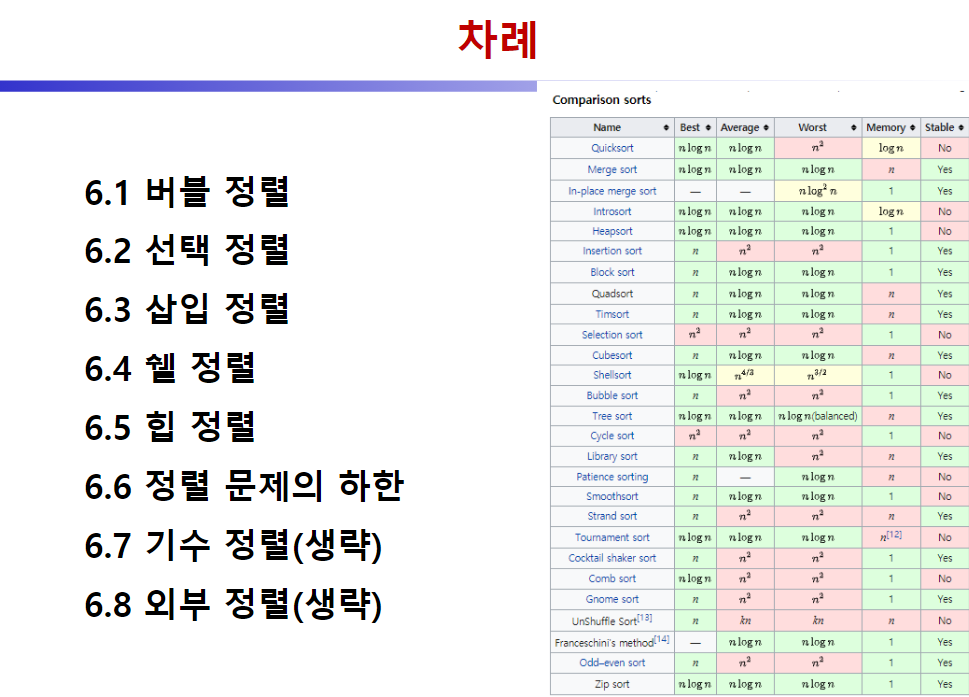
많은 정렬이 있는데 결국 쓰이는 좋은 정렬의 조건은
1. 시간복잡도가 낮을 것(평균, 베스트, 워스트 케이스 모두에서. 특히 평균의 경우)
2. 메모리 사용 크기가 적으면 좋음
3. 안정성이 있으면 좋음(안정성이란 만약 같은 값이 있을 때, 정렬을 할 때마다 순서가 바뀌지 않고, 항상 원래 있던 선후 관계를 뒤바꾸지 않고 일정하게 나오는 것)
이 정도이다.

chatGPT에게 가장 효율적이고 널리 사용되는 정렬 알고리즘을 묻자 퀵정렬, 병합정렬, Heapsort, Timsort 정도가 있었다.(나중에 쓰겠지만 현재까지는 O(n log n)이 시간복잡도 면에서 가장 효율적이다) 데이터 세트의 크기, 분포, 안정성 등에 따라 사용되는 알고리즘은 다르지만 버블 정렬같이 시간복잡도가 O(n^2)가 나오는 구진 정렬은 아무도 안 쓸것 같다. 그럼에도 왜 쓰지도 않는 알고리즘부터 배우는 걸까? 역시 chatGPT에게 물어보았다.

정리해 보자면 선택 정렬, 버블 정렬을 공부하는 이유는
1. 선택 정렬과 버블 정렬은 쉬우니까 이것을 통해 알고리즘 설계의 기본 개념인 반복, 재귀, 분할 정복 등을 학습한다.
2. 역사적 중요성..은 잘 모르겠다. 알고리즘이 이렇게 진화해왔다는 것을 확인하는 것이 인사이트를 늘리는데 도움을 주려나?
3. 이 알고리즘의 성능을 효율적인 알고리즘과 비교해보며 시간 복잡성, 공간 복잡성 및 실제 성능에 대한 통찰력을 얻는다.
음.. 상당히 타당하다.
결론적으로 나는 저것을 공부하며 아래 내용을 챙기면 되겠다.
1. 반복,재귀,분할 정복 기본 개념을 학습하고
2. 나중에 효율적인 알고리즘을 학습한 후 비교해보며 시간 복잡성, 공간 복잡성, 실제 돌려보며 성능에 대해 느껴보자.
'개발 > 컴퓨터알고리즘' 카테고리의 다른 글
| 최대 숫자 찾기 - 순차 탐색 알고리즘(C언어) (0) | 2023.04.01 |
|---|